Today, data is an organization’s most valuable asset; however, without protection, it can turn into a major legal and financial risk. Sharing datasets containing PII (Personally Identifiable Information) is strictly regulated under privacy compliance. At this point, two fundamental concepts emerge: Data Masking and Data Anonymization.
So, where is the line drawn between these two methods? Which one is more secure for your business?

What Is Data Masking?
Data masking is the process of creating a structurally similar but de-identified copy of original data. It is typically used to protect sensitive information during software testing (test data management), user training, or analytical processes.
Smart data masking techniques vary depending on the data type. For example, showing only the last four digits of a credit card number (4543 **** **** 1234) is a classic example. The goal here is to restrict access without compromising the data’s functionality.
Data Masking vs Data Anonymization
While many professionals use these two terms interchangeably, there is a vast gap between them regarding regulations like GDPR and KVKK. Here are the 5 key differences you need to know:
1. Reversibility
- Data masking: It is generally reversible. Authorized users can still access the original data using decryption or re-identification keys.
- Data Anonymization: It is a one-way process. Once the anonymization process is complete, it is technically impossible to revert to the original identity.
2. Regulatory Compliance (GDPR & HIPAA)
- Data masking: Generally falls under “Pseudonymization.” Under this status, the information may still be legally considered “personal data.”
- Data Anonymization: By making the data truly anonymous, it exempts the organization from many heavy obligations under GDPR, HIPAA, and KVKK.
3. Intended Use
- Data masking: Ideal primarily for software development, testing, and training environments.
- Data Anonymization: The most secure method for data mining, public reporting, and training automation AI / Machine Learning models.
4. Implementation Techniques
- Data masking: Utilizes methods such as character masking, shuffling, or substitution.
- Data Anonymization: Employs techniques like data aggregation, differential privacy, or AI-powered data deletion.
5. Data Type and Context
Data masking is typically easy to apply to structured data, such as tables or SQL databases. However, the process becomes complex when dealing with free text, emails, or documents.
At this point, text anonymization technologies—capable of decoding deep meanings within text—act as the most modern barrier to preventing data breaches.
Industry Use Cases and Real-World Scenarios
Today, data security is a critical requirement not just for regulatory compliance, but for the sustainability of business operations.
Masking and data anonymization solutions address different needs across various industries. Choosing the right method directly impacts both the protection of sensitive data and the continuity of your business.
🏥 Healthcare Sector (HIPAA Compliance)
Hospitals and medical research organizations must protect personal data while performing analysis and modeling on patient records.
In these scenarios, patient names, ID numbers, and contact information are obscured using a Document Redaction Tool. This allows medical histories and clinical data to be safely used in scientific research without creating any identity risks.
🏦 Finans ve Bankacılık
In the financial sector, data access cannot operate on an “everyone sees everything” basis. Customer service and operations teams should only see the data necessary for their specific tasks.
Thanks to AI-powered data masking solutions, customer representatives see only the portion of critical information—such as card numbers, national IDs, or IBANs—required to perform a transaction, rather than the full details. This approach both reduces internal threat risks and simplifies auditing processes.
💻 Software Development and Testing Processes
Allowing development teams to work with real user data poses a significant security risk. Therefore, production data is transformed using data anonymization methods before being transferred to test and development environments.
By using anonymized datasets, software teams can test applications under conditions that mimic real-world scenarios while maintaining full privacy compliance.
📊 Extra Use Case – Data Analytics & AI Projects
Organizations face PII risks when they want to analyze customer feedback, call center records, or reports containing free text. At this point, text anonymization and smart data masking solutions prevent the exposure of personal information while keeping the data in an analyzable format.
This ensures that AI models are trained with secure data and that insight generation remains uninterrupted.
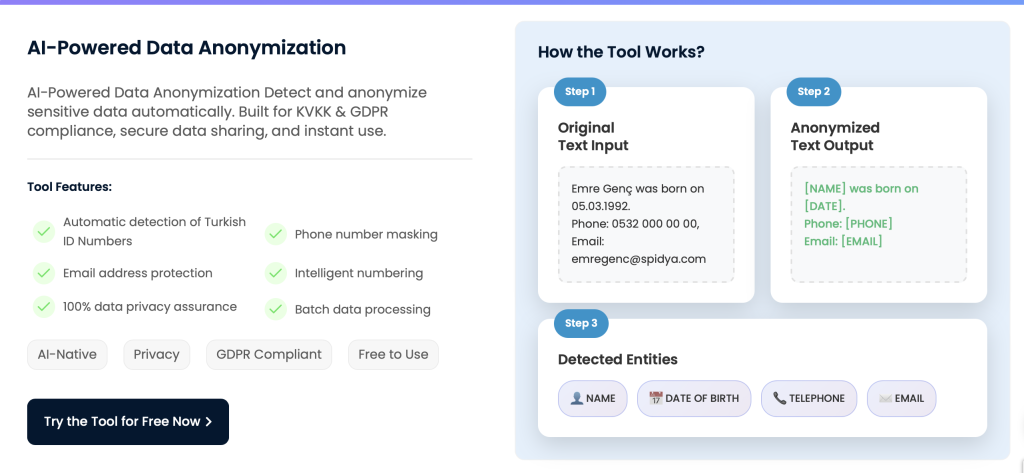
Meet Our Free AI-Powered Data Anonymization Tool!
While traditional methods succeed with static data, they often fall short in detecting sensitive information hidden within “free text” (such as chat logs or support tickets).
The SPIDYA AI Data Anonymization Tool identifies addresses, names, and financial data within text without losing the context. Operating on the principle of the Intelligent Protection of Personal Data, this system performs smart text anonymization—ensuring security without compromising the data’s analytical value.
Why Should You Use a Data Anonymization Tool?
Speed: Completes document redaction tool processes—which would manually take hours—in just seconds.
Accuracy: Detects PII data that might be overlooked by the human eye with high precision.
Cost: You can start with free tool options and significantly reduce your operational workload.
Frequently Asked Questions About Data Masking
What is Data Masking in Brief?
Data masking is the process of hiding sensitive data from unauthorized users by modifying characters or values without altering the data’s structural properties.
What is the Biggest Difference Between Data Anonymization and Masking?
The most significant difference is reversibility; while masked data can be restored to its original state using specific keys, anonymized data is permanently de-identified.
Is There a Free Data Anonymization Tool?
SPIDYA Software’s AI-powered modern platform provides users with free tool options that allow for PII detection and protection within seconds.
Conclusion: Which Method Should You Choose?
If your goal is simply to create a secure testing environment, data masking may be sufficient. However, if you aim to share your data, analyze it, or utilize it in AI models, data anonymization is your only viable option.
Remember: every leaked data point is a penalty risk, whereas every anonymized data point is an asset.






