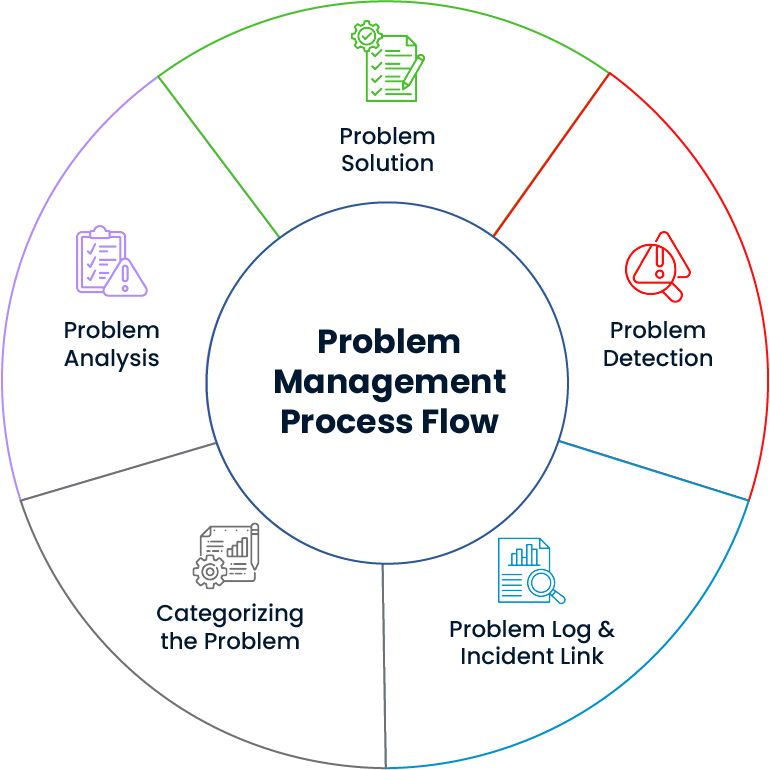
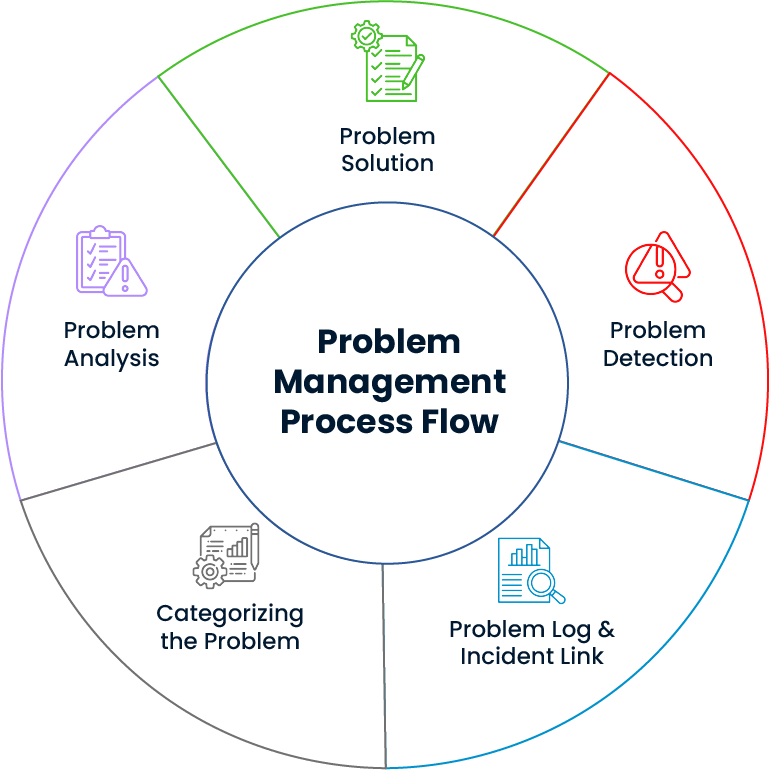





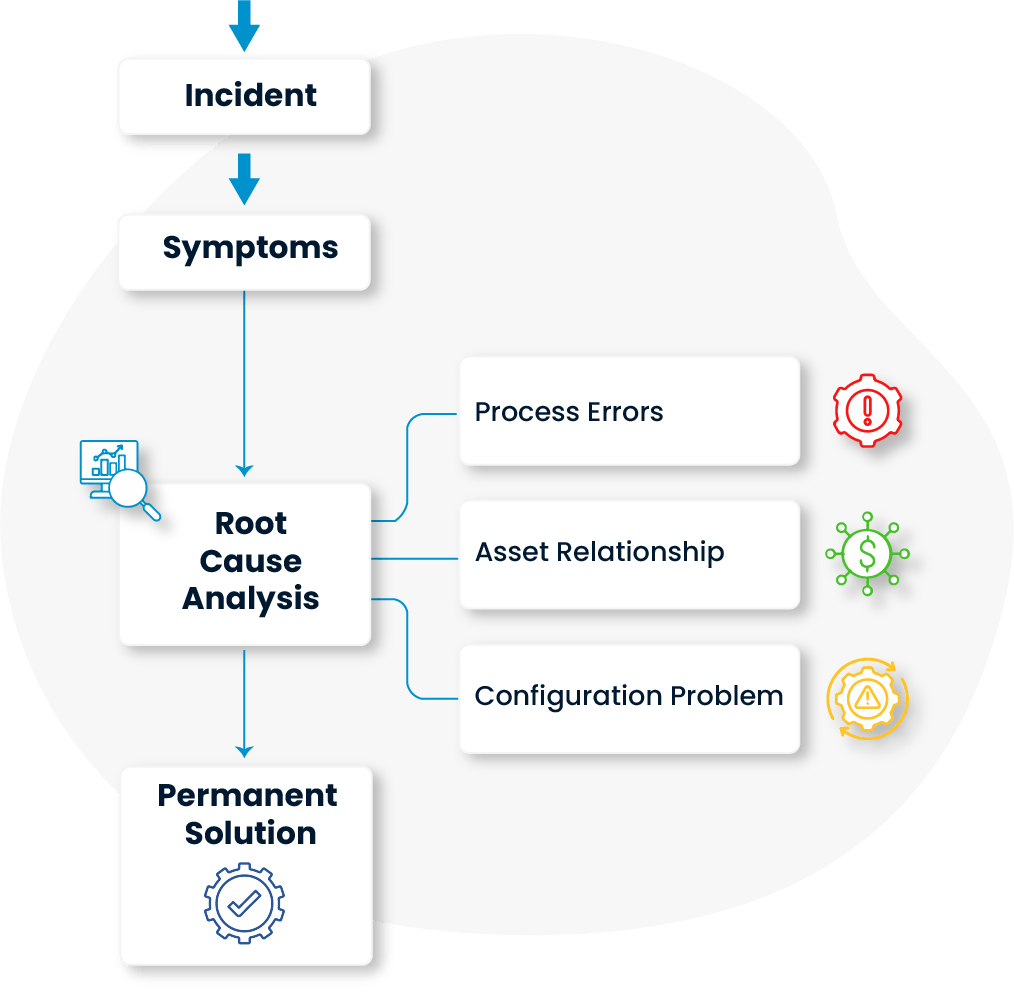
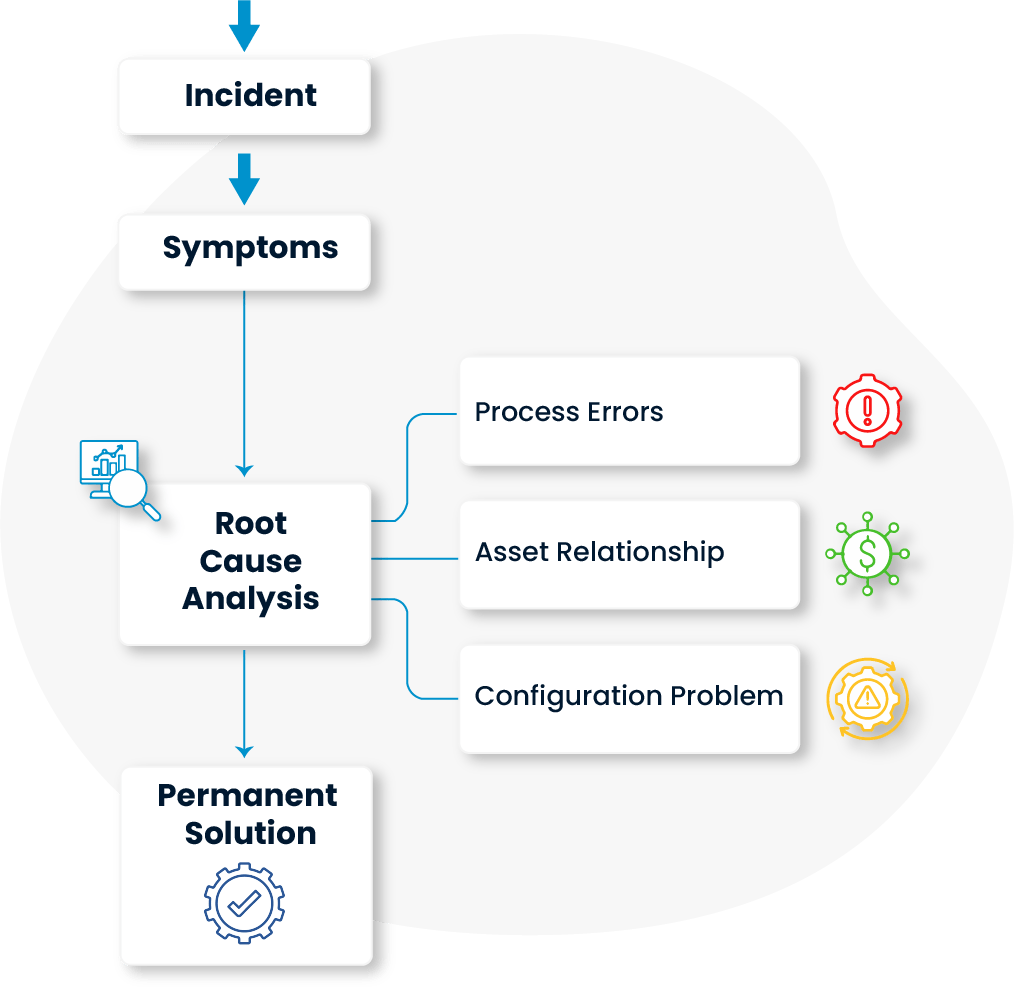

The true underlying causes of incidents are uncovered through detailed analysis. In this process, not only the symptoms are addressed via incident management, but also the contributing processes and factors related to asset and configuration management are improved. This creates a solid foundation for delivering permanent solutions.
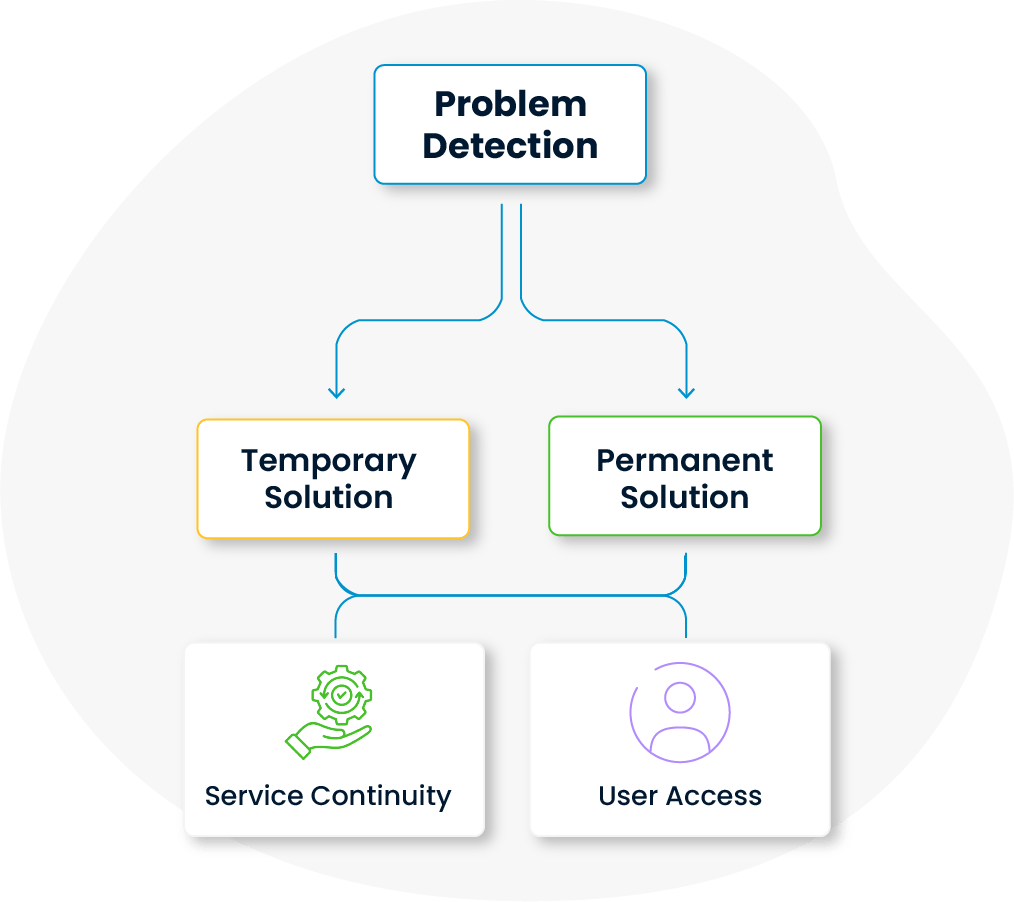
Until a permanent resolution is found, temporary measures are implemented in line with problem management principles to ensure service continuity.
These steps allow users to continue their business processes without disruption and help protect against operational setbacks.
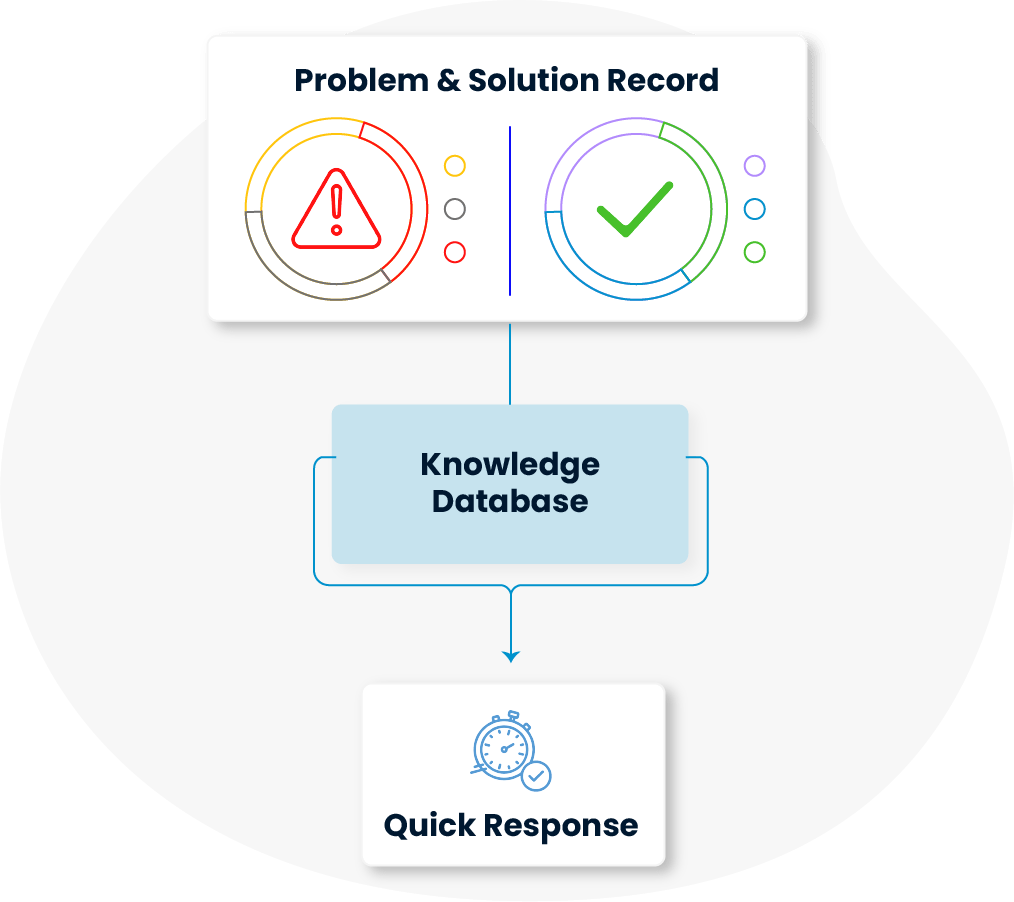
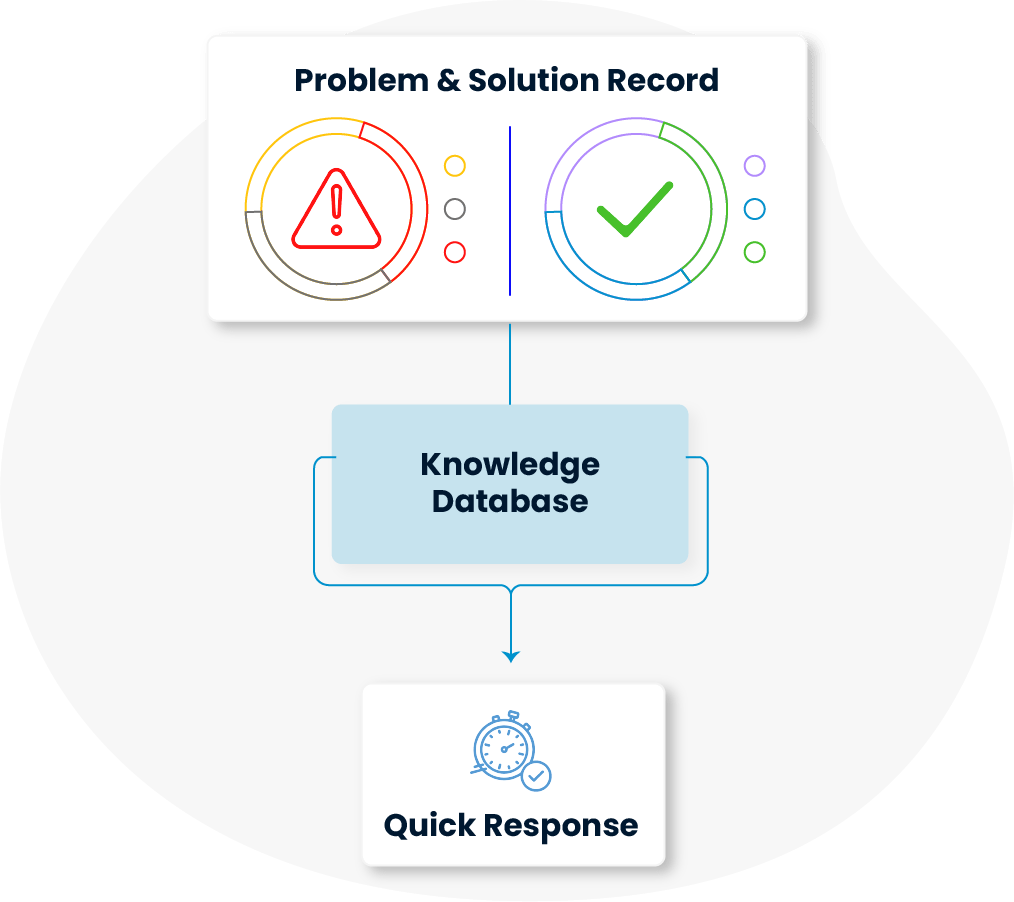
Past problems and their resolutions are systematically recorded and organized within the platform. This structure creates a knowledge base as part of this module, enabling teams to respond quickly and effectively when similar issues arise.
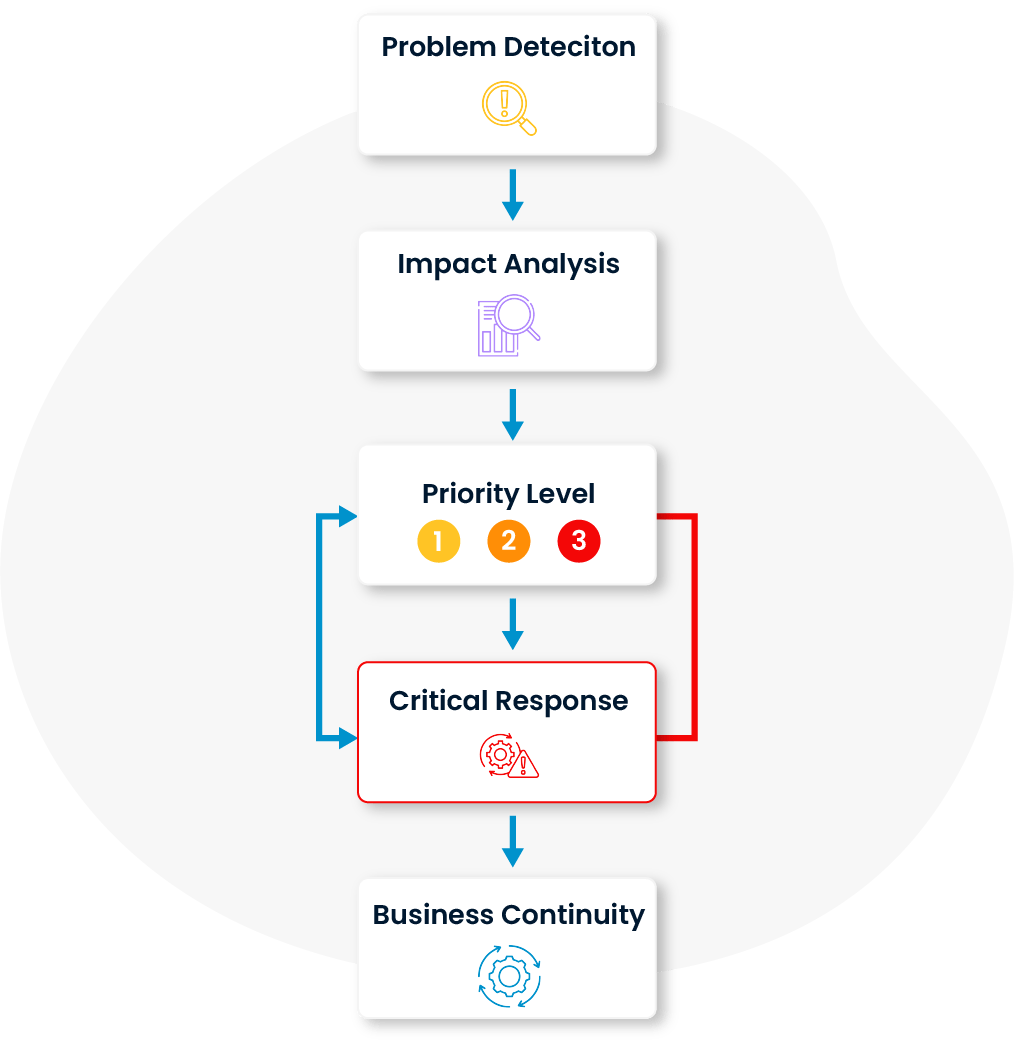
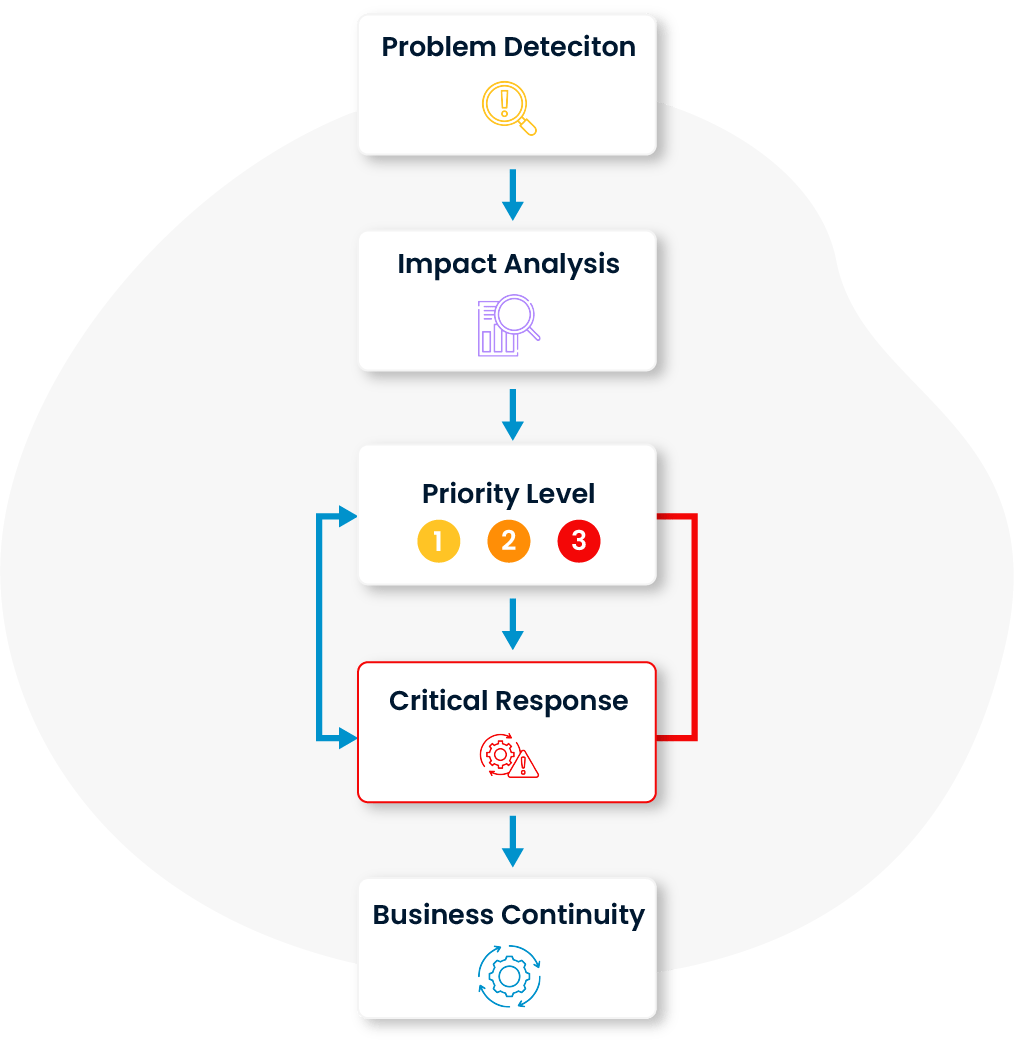
The impact of problems on IT services is thoroughly analyzed and prioritized accordingly. This ensures that issues affecting the most critical systems are addressed first, incident management processes are handled efficiently, and business continuity is maintained.
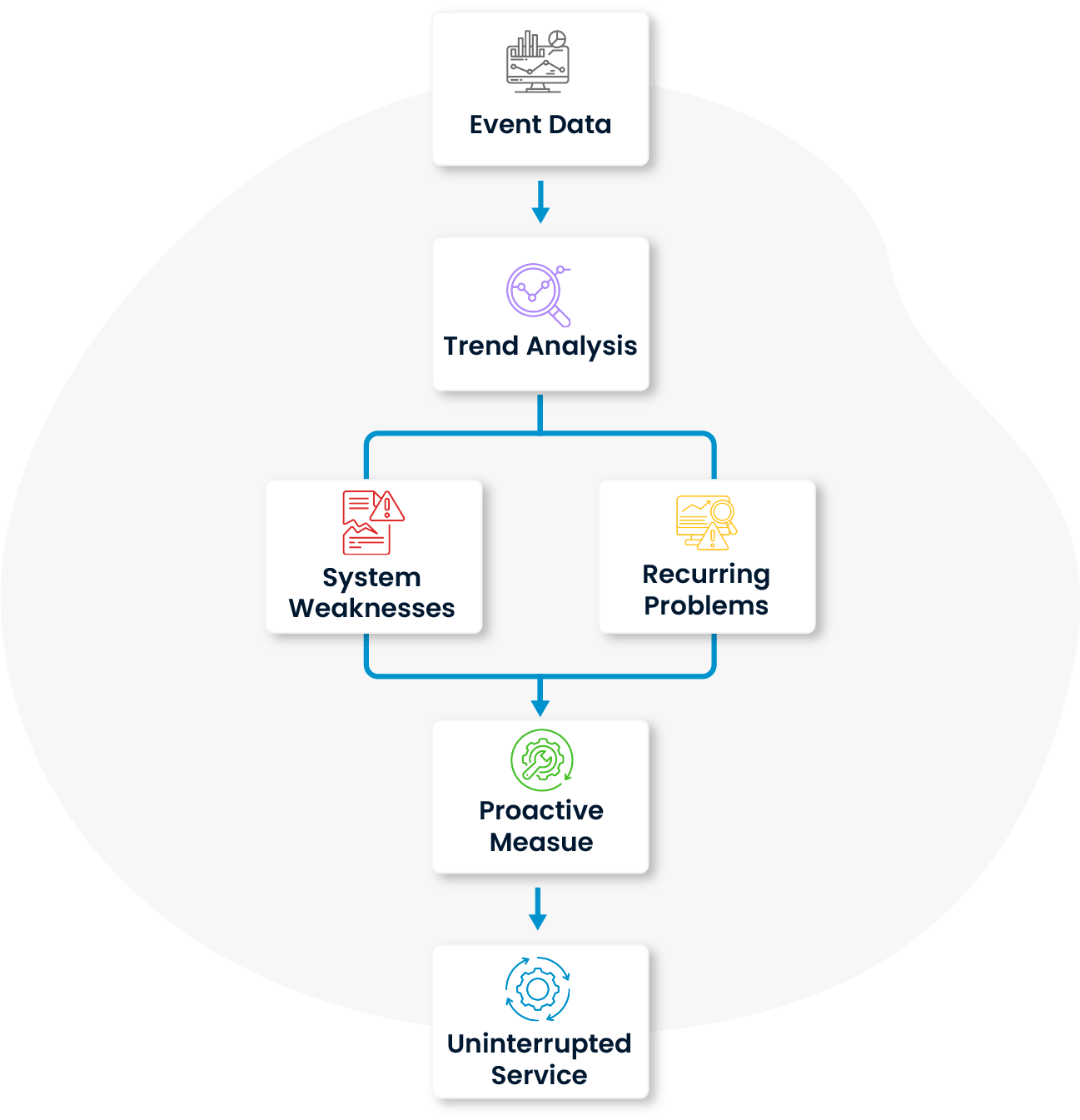
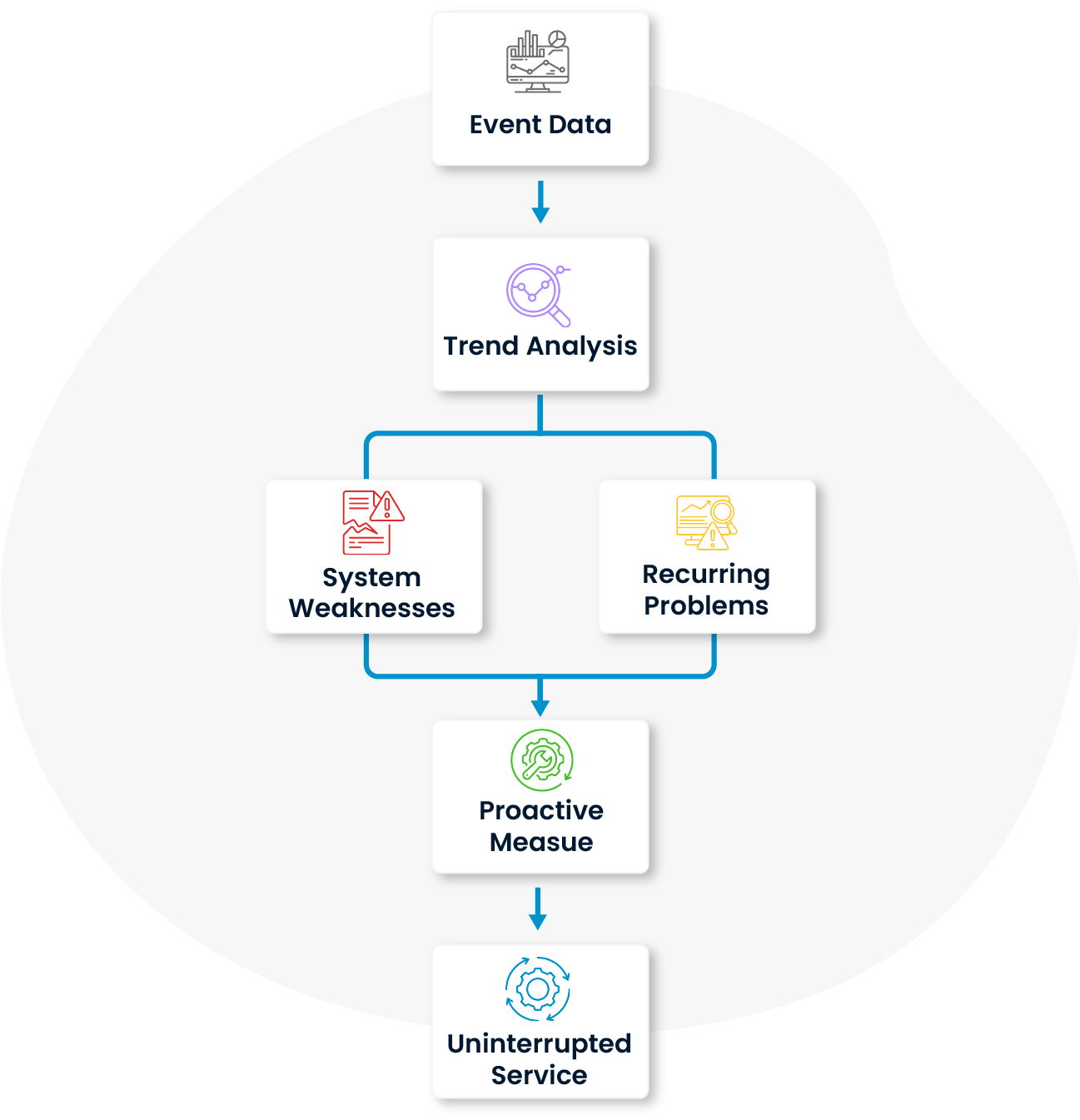
The likelihood of incident recurrence is analyzed to identify similar patterns and system vulnerabilities in advance. This enables error control mechanisms to activate and strategic steps to be taken for uninterrupted service delivery in the IT infrastructure.
The true underlying causes of incidents are uncovered through detailed analysis. In this process, not only the symptoms are addressed via incident management, but also the contributing processes and factors related to asset and configuration management are improved. This creates a solid foundation for delivering permanent solutions.
Until a permanent resolution is found, temporary measures are implemented in line with problem management principles to ensure service continuity.
These interim steps allow users to continue their business processes without disruption and help protect against operational setbacks.
Past problems and their resolutions are systematically recorded and organized within the system. This structure creates a knowledge base as part of problem management, enabling teams to respond quickly and effectively when similar issues arise.
The impact of problems on IT services is thoroughly analyzed and prioritized accordingly. This ensures that issues affecting the most critical systems are addressed first, incident management processes are handled efficiently, and business continuity is maintained.
The likelihood of incident recurrence is analyzed to identify similar patterns and system vulnerabilities in advance. This enables error control mechanisms to activate and strategic steps to be taken for uninterrupted service delivery in the IT infrastructure.
