




Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90
Warning: Undefined array key "background_image" in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 87
Warning: Trying to access array offset on null in /home/spidya/htdocs/spidya.com/wp-content/plugins/elementor/includes/conditions.php on line 90

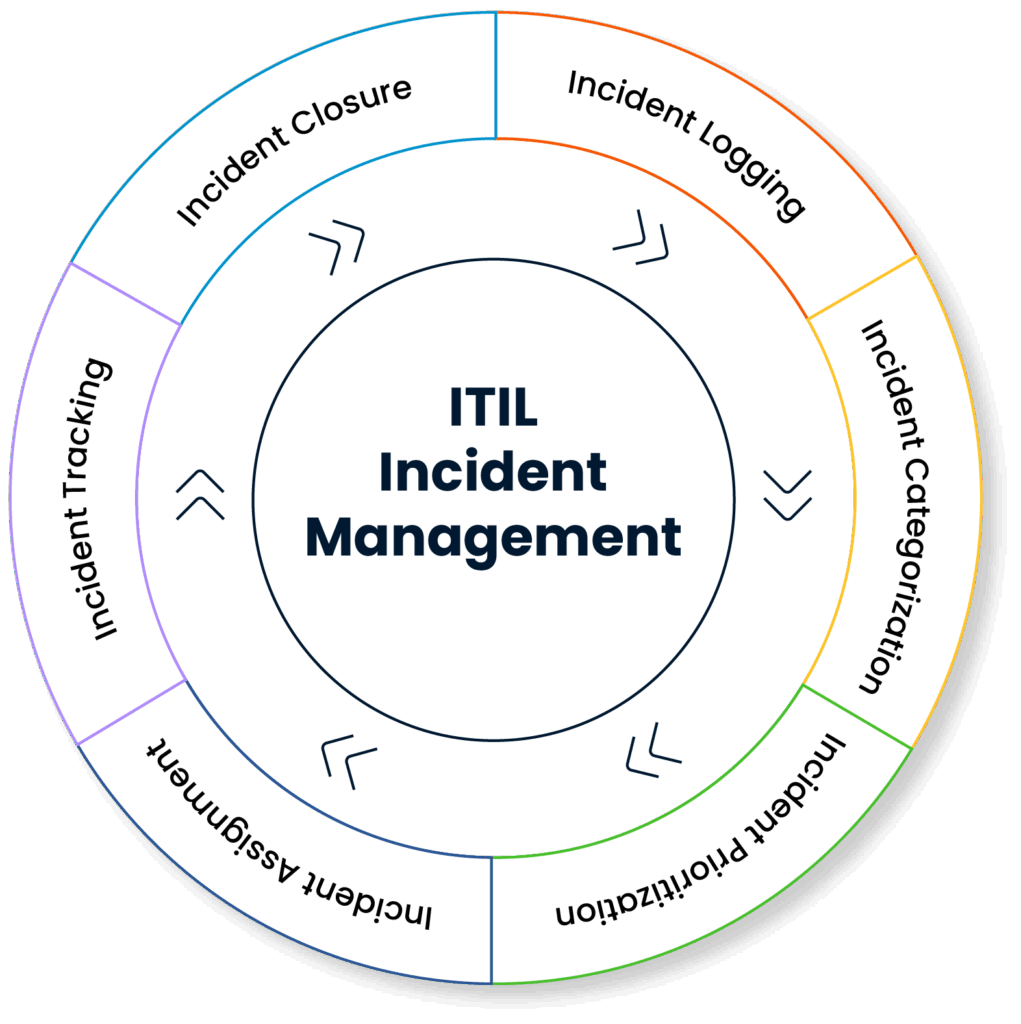
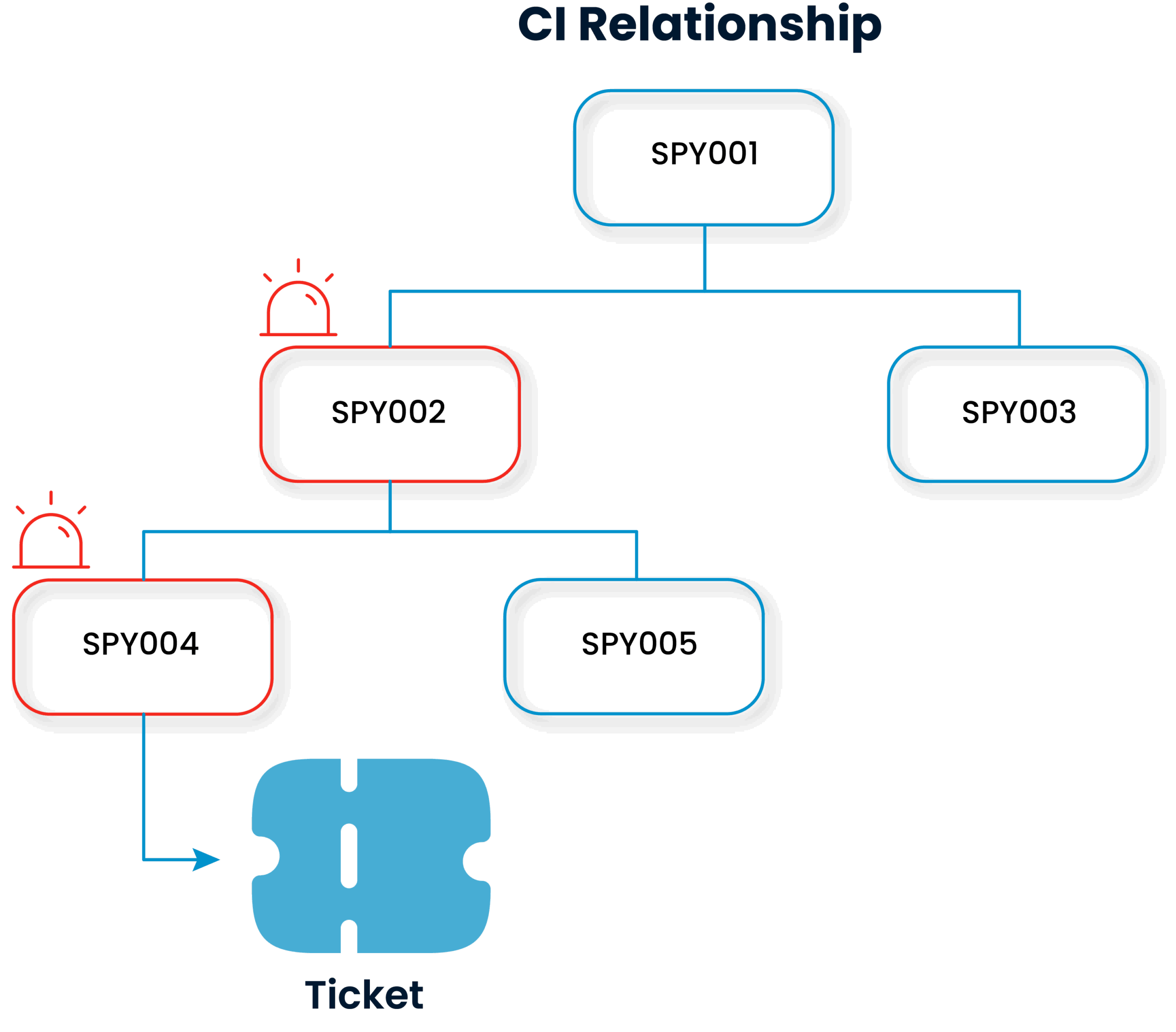
Incidents generated by users or systems are quickly logged into the system and processes are initiated without delay.
Each incident is classified and prioritized in line with predefined rules, so that the problem log is automatically created, making it easier to track critical incidents.
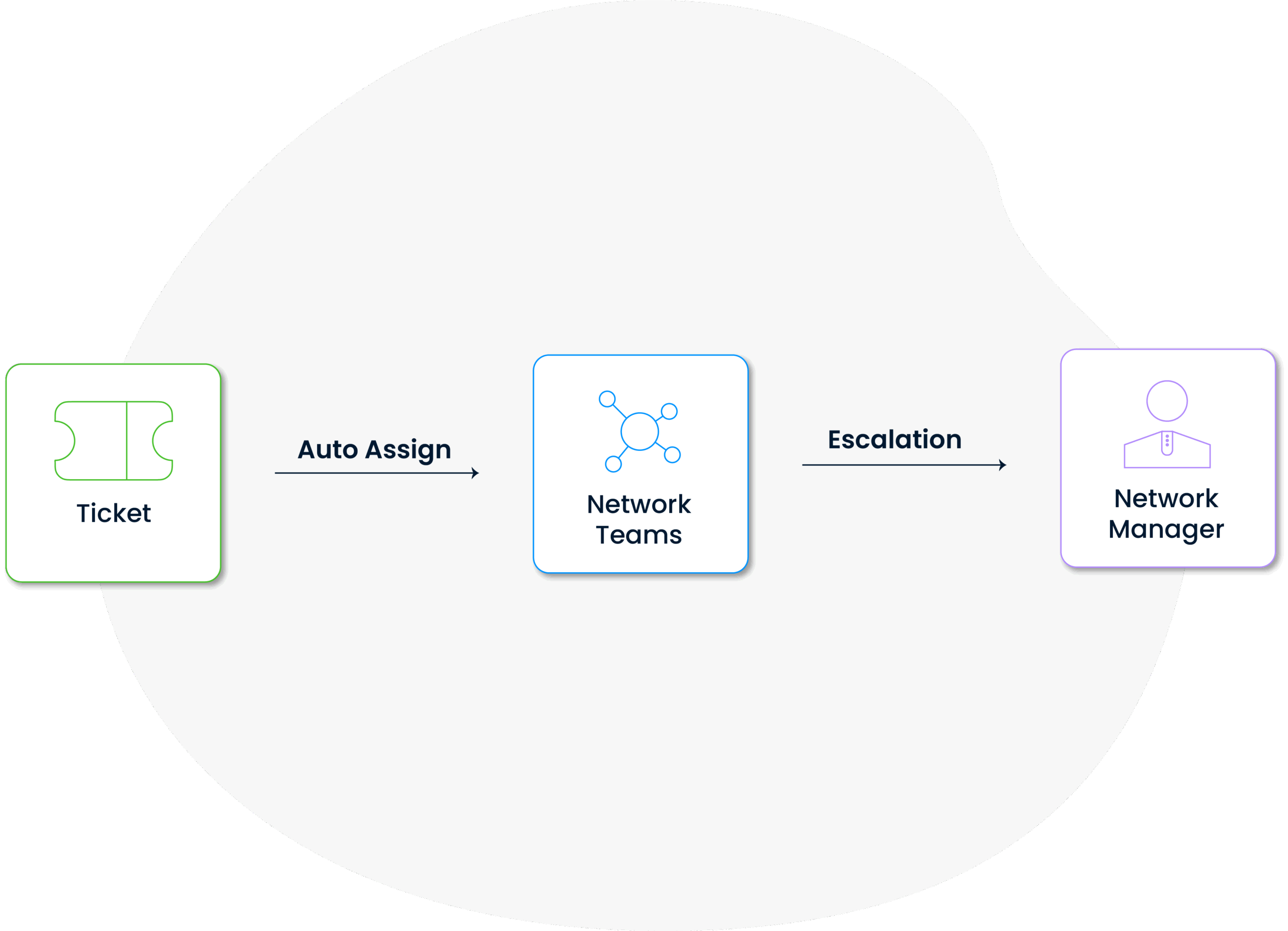
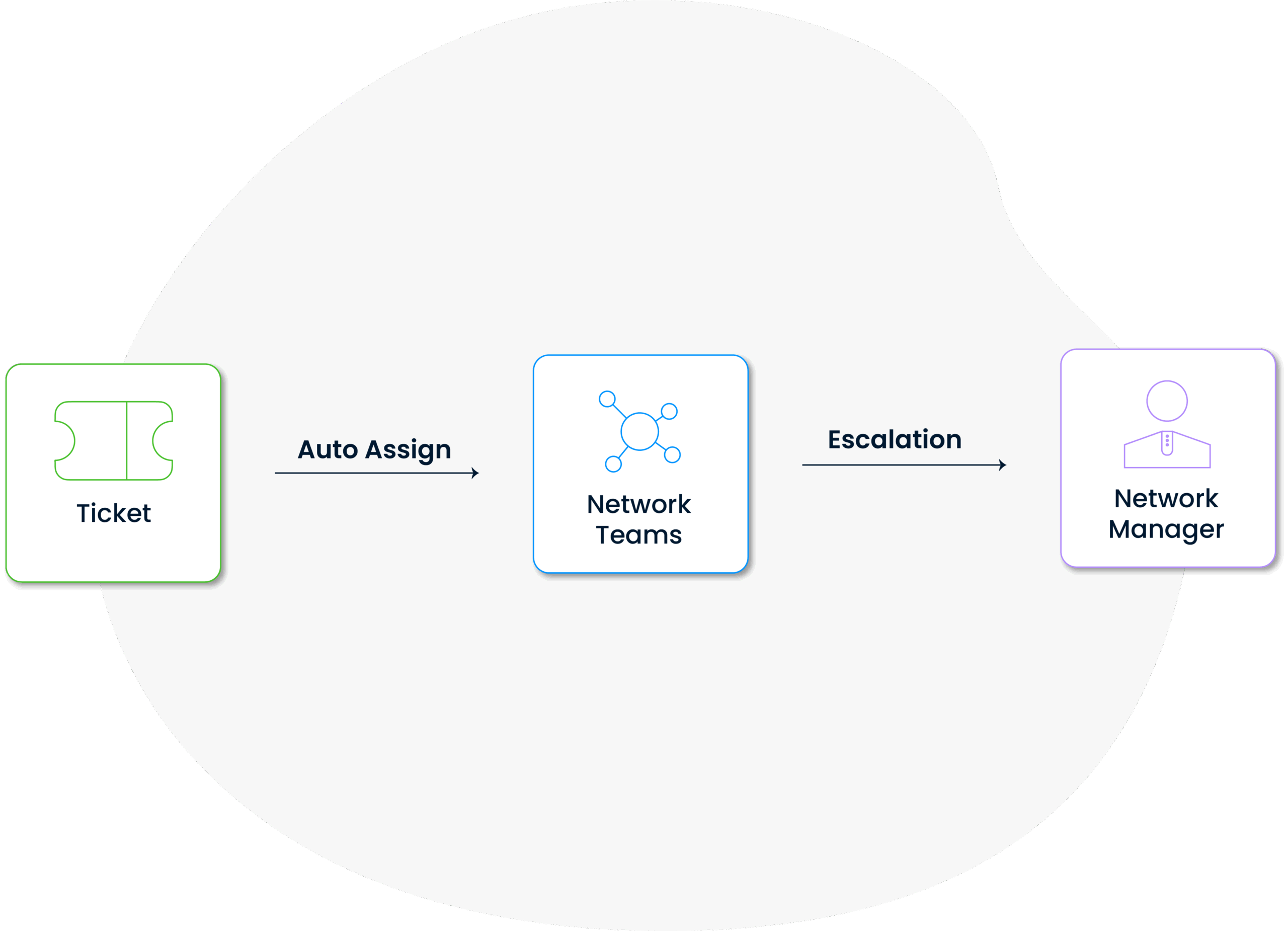
The system automatically assigns the entered incidents to the relevant teams or individuals according to their content and importance levels. This ensures that incidents are resolved correctly and time management is optimized.
In critical situations, incidents are automatically escalated to a higher level within the framework of defined rules, thus preventing time loss, ensuring rapid response and guaranteeing service continuity.
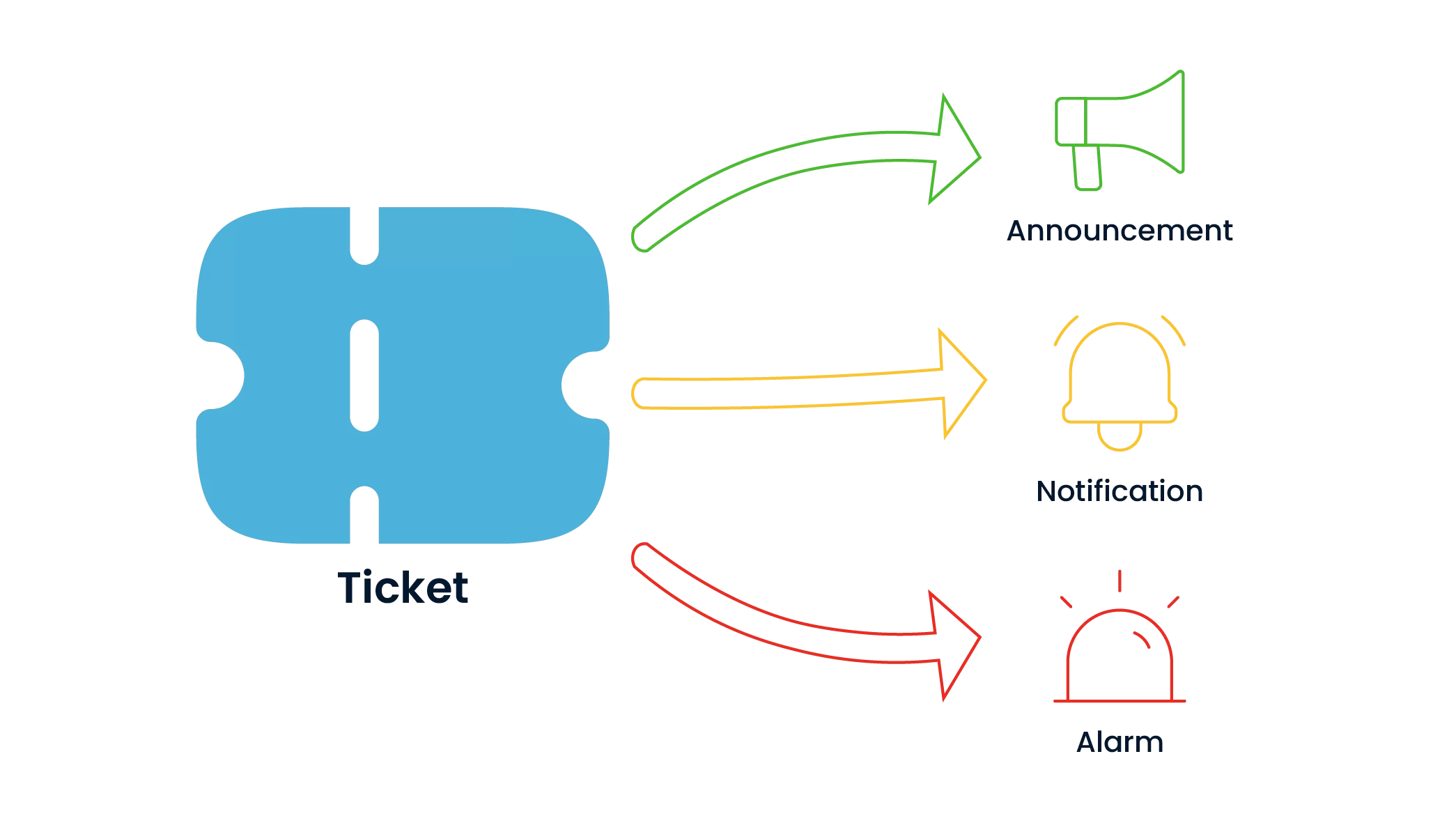
Any status change related to an incident is detected and both the relevant teams and users are immediately informed. This mechanism prevents information gaps and communication breakdowns and ensures that all stakeholders have up-to-date information throughout the incident management process.
AI analyzes which systems, services or user groups each incident affects. These analyses clarify the impact of the incident on business processes and allow prioritization decisions to be made more strategically.
Resources are used more efficiently and response plans are created more effectively according to the criticality of the incident. Thus, the impact of failures on the business is minimized and operational efficiency is maintained.
For recurring incidents, artificial intelligence enables a detailed root cause analysis. In this way, structural improvements that will eliminate the root causes of incidents are implemented, not just temporary solutions.
The process both solves today ' s problems and develops a problem-oriented service approach by preventing similar incidents in the future.
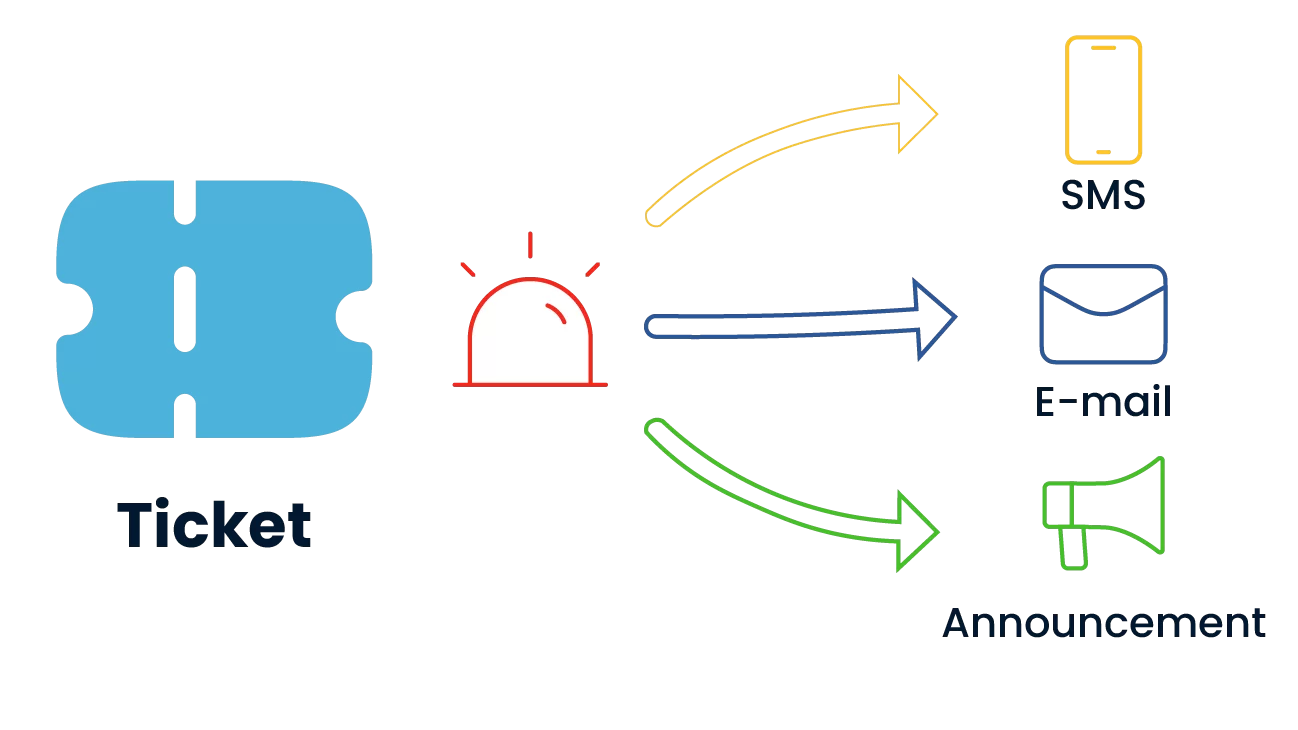
Developments related to each stage of the incident are automatically communicated to the relevant users and team members via e-mail, SMS or in-system notification. This structure increases the active participation of the parties throughout the entire process, increases the speed of decision-making and minimizes possible delays.
By providing a transparent and uninterrupted tracking environment, problem logging and intervention history becomes clearly traceable.
Incidents generated by users or systems are quickly logged into the system and processes are initiated without delay.
Each incident is classified and prioritized in line with predefined rules, so that the problem log is automatically created, making it easier to track critical incidents.
The system automatically assigns the entered incidents to the relevant teams or individuals according to their content and importance levels. This ensures that incidents are resolved correctly and time management is optimized.
In critical situations, incidents are automatically escalated to a higher level within the framework of defined rules, thus preventing time loss, ensuring rapid response and guaranteeing service continuity.
Any status change related to an incident is detected by the system and both the relevant teams and users are immediately informed. This mechanism prevents information gaps and communication breakdowns and ensures that all stakeholders have up-to-date information throughout the incident management process.
AI analyzes which systems, services or user groups each incident affects. These analyses clarify the impact of the incident on business processes and allow prioritization decisions to be made more strategically.
Resources are used more efficiently and response plans are created more effectively according to the criticality of the incident. Thus, the impact of failures on the business is minimized and operational efficiency is maintained.
For recurring incidents, artificial intelligence enables a detailed root cause analysis. In this way, structural improvements that will eliminate the root causes of incidents are implemented, not just temporary solutions.
The process both solves today ' s problems and develops a problem-oriented service approach by preventing similar incidents in the future.
Developments related to each stage of the incident are automatically communicated to the relevant users and team members via e-mail, SMS or in-system notification. This structure increases the active participation of the parties throughout the entire process, increases the speed of decision-making and minimizes possible delays.
By providing a transparent and uninterrupted tracking environment, problem logging and intervention history becomes clearly traceable.